AI Privacy
AI Privacy Audits with Membership Inference Attacks
As the EU AI Act is about to be finalised and put into practice, major new regulatory challenges arise for companies adopting Generative AI, particularly in the domain of privacy. Article 6 of the act’s draft names AI applications within the broad domain of “employment and workforce management” as a high-risk area that requires additional rigorous evaluation before putting use cases into production. Given these demands, it is clear that companies need a way to audit machine learning models to avoid fines and manage risk. In this article, we’re presenting membership inference attacks as a tool that can be utilized to audit AI privacy.
What is a Membership Inference Attack?
Membership inference attacks (MIAs) were not necessarily designed as an auditing tool, but discovered by researchers as a source of risk, that - as the name suggests - actors with malicious intentions could use to carry out attacks to extract information about a machine learning model’s training data. Concretely, the task of an MIA is a classification task: given a single data point and a model, its objective is to determine whether that data point was part of the model’s training set.
It turns out that, even without access to model weights and merely confidence scores or the predictions themselves, it is very much possible to identify training data, particularly when a model wasn’t trained with regularization techniques or when it has overfit its training data. In a paper from 2018, researchers from Carnegie Mellon University were able to identify training data from the CIFAR-100 image classification dataset with an accuracy of more than 87% by merely setting a threshold value and checking if a model’s confidence for a data point is above a certain threshold. Over the years, researchers have come up with more sophisticated attacks that reveal even higher risks.
Generative AI brings higher risk than classical Machine Learning models
As companies start to adopt generative AI models that generate data rather than just classify or cluster it, the associated privacy risks are even bigger. The simple reason for this is that generative models might simply recreate part of their training data or prompts without requiring the intent of attacking the model. In 2020, researchers from Google, OpenAI and other institutions revealed that, with intelligent prompting, they were able to extract sensitive aspects of the training data of GPT-2, including PII such as e-mail or physical addresses. More recently, it was discovered that diffusion models, which are used to generate images,reveal exact replications of their training data when generating large amounts of images.

Membership Inference Attacks for Privacy Audits
While the leakage of training data from a generative AI model can have severe consequences, it is also a relatively rare event. This makes it difficult to design experiments that draw meaningful quantitative conclusions about data leakage: Reliably detecting quantitative changes about the frequency of an event that might only happen with, say, every 100,000th or millionth model query, is highly expensive and time-consuming, as it would need a huge amount of experimental runs to confidently detect changes. Particularly for generative models that are expensive to run, evaluation on this scale is an unrealistic endeavour.
This is where membership inference attacks come into play: Clearly, it is intuitive that the more prone a model is to leaking certain data points, the easier it is to identify them through membership inference attacks. Conveniently, a large body of work proposing defenses against data leakage has verified that a model’s tendency to leak training data is highly correlated with its susceptibility to membership inference attacks. This gives us a way to reliably measure the data leakage of a machine learning model with realistic amounts of resources!
Measuring LLM Data Leakage with Neighbour Attacks
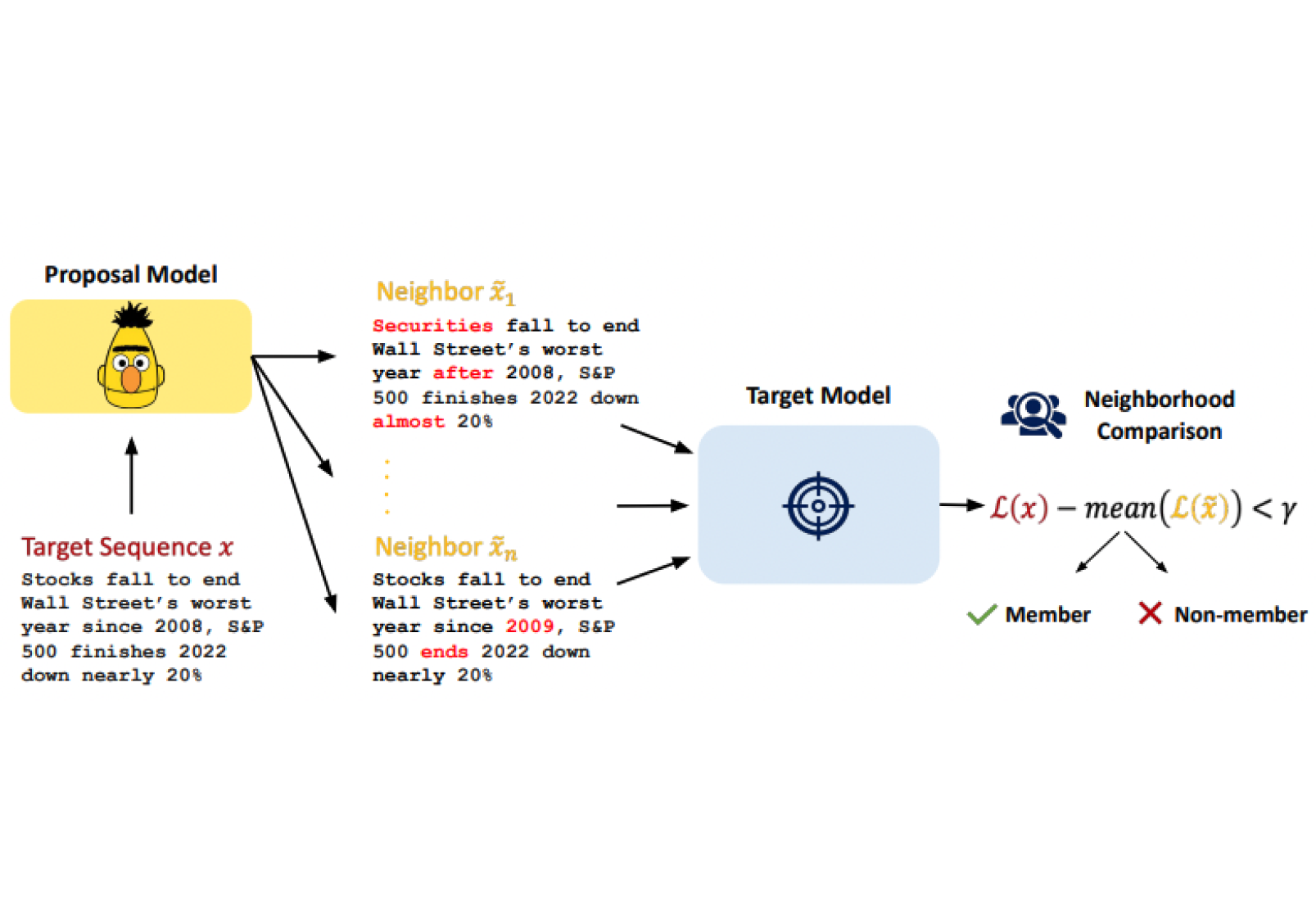
A concrete example of membership inference attacks that can be used to measure training data leakage from large language models are neighbourhood attacks, which were previously published by Haven's founders themselves and are among the most powerful MIAs to date. Neighbourhood attacks are based on the simple assumption that LLMs assign higher likelihoods to textual snippets that they were trained on than others. However, simply thresholding the likelihood of texts to determine if they are part of a model’s training data or not does not take into account the intrinsic complexity of the data itself. For instance, the textual sample “Jack Smith plays tennis” would most likely be assigned a higher likelihood than “Zephyr Huckleberry plays underwater pumpkin carving”, even if the latter was part of a model’s training data, as the former sentence is a much more common one.
To address this issue, neigbourhood attacks generate neighbour texts, which are very similar to the original textual snippet, but only differ by a few semantically coherent word replacements, and are used to give an estimate of a sample’s inherent complexity. By regularizing the confidence scores for a particular sample using the confidence scores of the neighbour samples, we are able to obtain a substantially more accurate signal about the memorization of training data.
As a concrete example that Haven has evaluated with a client, let’s assume that we are building a customer support chatbot and have fine-tuned a GPT-3.5 model on customer email exchanges with the company’s support staff. To perform a privacy audit, we can leverage a masked language model like BERT to generate neighbours and compute the confidence scores of the fine-tuned model divided by the scores of the sample's neighbours on both training data and non-training data. For maximum privacy, we want the difference in the average value of these ratios to be minimal - if this is the case, we can confidently deploy our model!